10 EIQ_AI 軟體試作版完成
開發目的為:
1. 在不使用額外追加出貨資料的情況下,直接根據現有資料模擬出貨物量的增減。
2. 於公司內部的電腦(PC)上運行,以確保出貨資料的機密性,操作人員可在需要時隨時輕鬆使用。
3. 作為物流 AI 的一個範例,利用實際的出貨資料來學習軟體的內容與作業流程。
本 EIQ_AI 軟體在大學結束試作版的使用後,最終完成版將會免費對外公開。
1)出貨資料的刪除與追加邏輯
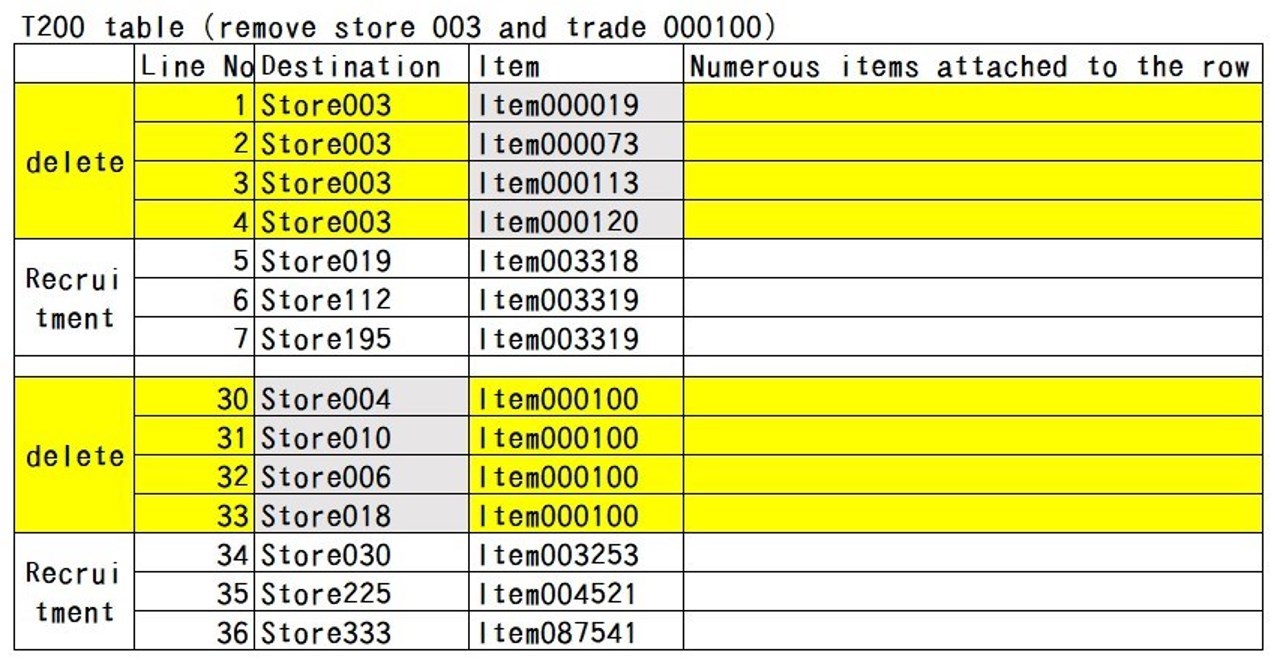
伴隨出貨目的地數(E)與品項數(I)增減而產生的統計變化,皆屬於碎形結構。也就是說,這就如同銀杏葉不論大小如何變化,都依然保持著銀杏葉的形狀。若「店003」這個出貨目的地消失了,則「店003」的紀錄(Record)就會消失;若「商000100」這個品項消失了,則「商000100」品項的紀錄就會消失。
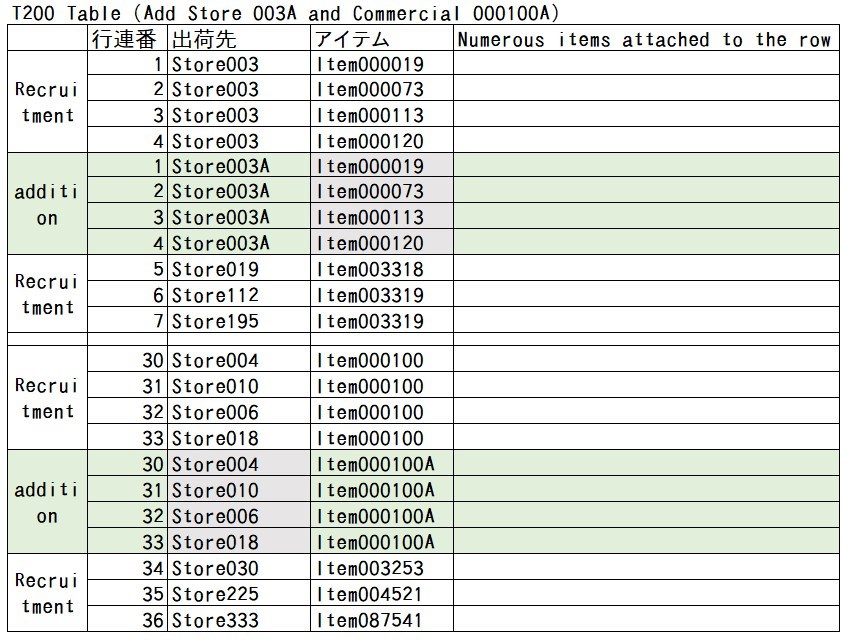
反之,若追加了與「店003」等同的出貨目的地「店003A」,則會追加與「店003」等同的紀錄;若追加了與「商000100」品項等同的「商000100A」,則會追加與「商000100」品項等同的紀錄。
2)如何決定哪些出貨目的地或品項為刪除、追加的對象
在建立 EIQ_AI 模型資料的階段,無法直接指定要刪除或追加的出貨目的地和品項。因此,我們使用「蒙地卡羅法」來決定刪除與追加的對象。為所有的出貨目的地及品項分配一個 0 到 1 之間的亂數(隨機數),並設定「E 判定基準 = 計算出貨目的地數 / 原始出貨資料的出貨目的地數」。凡是高於 E 判定基準(例如設為 0.7)的出貨目的地即予以刪除。而關於追加,當 E 判定基準為(例如 1.25)時,則以「E 判定基準 ─ 1」亦即 0.25 的比例,變更出貨目的地名稱(如「店003A」)後來進行追加。
關於這些軟體開發邏輯的詳細內容,請參閱 Tera計算 EIQ_AI 整合入口網站。